Python爬虫解析库-XPath
除了使用正则表达式提取网页中数据之外, XPath也是一个强大的网页文本内容提取工具, XPath全称XML Path Language, 即XML路径语言, 最初用来在XML文档的, 但是同样适用于HTML文档的搜索.
1. 安装
1 | pip install lxml |
2. XPath常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选择直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
3. html文本引入和预处理
文本引入可以在内存中和外部文件中获取.
tostring函数可以对一段html文本进行完善和补全(自动修正), 如果缺少某个封闭标记, 执行后可以添加上去.
1 | from lxml import etree |
1 | html = etree.parse('./test.html', etree.HTMLParser()) |
4. 具体内容
1. 所有节点
我们一般会用//开头的XPath规则来选取所有符合要求的节点.
例如:
(1) //*: 获取所有节点
(2) //li: 获取所有子孙节点中的li节点
1 | html.xpath("//*") #这里html是XPath对象, 返回的是列表对象 |
2. 子节点
通过//或/来获取所有子孙节点或直接子节点.
例如:
(1) //li/a: 获取所有li节点的直接子节点a
(2) //li//a: 获取所有li节点中的所有子孙节点a
3. 父节点
通过..来获取父节点, 这里需要注意/的作用
1 | text = """ |
上面使用//div[@data-id=”26849758”]来先找出所有属性为该属性的div节点, 再用..找出父节点, 最后使用@href来获取父节点的href属性
4. 属性匹配和属性获取
属性匹配中[]括起来的内容表示选取节点的条件, 使用@表示属性, 不用方括号使用@表示直接属性的获取
具体案例看上节父节点相关内容
5. 文本内容获取
我们使用text()来获取节点中的文本
例:
//a//text(): 获取所有li节点的内容
需要注意的是, 在获取一个节点的内容,其子孙节点的内容是不会被获取的, 并且经常加载\n等符号, 使得结果不纯净, 还需要在提取
6. 属性多值匹配
有时候一个属性有多个值, 这时需要使用contains来提取
1 | from lxml import etree |
上面例子中, li的class属性有两个值, li和li-first,如果直接用//li[@class=”li”]/a/text()就会获取不到了.
利用contains可以有效解决这一问题
PS: 在实际测试中,发现直接写@class=”li li-first”也能获取出来…
7. 多属性匹配
有时候一个节点有多个属性, 如果要精确定位该节点, 可以使用多个属性值来定位.
1 | from lxml import etree |
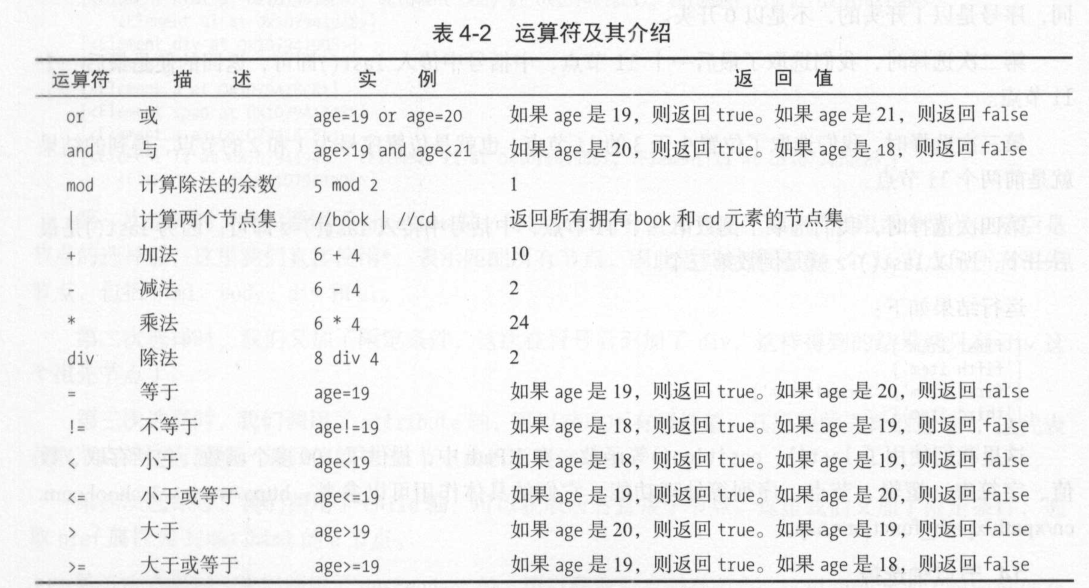
拓展: XPath运算符
8. 按序选择
有时候在选择某些属性的时候可能匹配了多个节点, 但是指向要其中的某个节点, 第一个节点等, 这时候可以使用中括号传入索引的方法获取特定次序的节点.
1 | html.xpath('//li[1]/a/text()') #获取第一个节点, 注意是序号从1开始 |
拓展: XPath函数
具体看网址: https://www.w3school.com.cn/xpath/xpath_functions.asp
9. XPath节点轴
具体看网址: https://www.w3school.com.cn/xpath/xpath_axes.asp
参考
- 崔庆才: 《Python3网络爬虫开发实战》
- W3C_School: https://www.w3school.com.cn/xpath/xpath_syntax.asp